Deep learning
딥러닝 기초
인공지능 vs ML vs DL
- 인공지능: 사람의 지능을 모방하여 분류하는 알고리즘
- ML: 데이터를 기반으로 학습하는 알고리즘
- DL: 인공신경망을 통해 데이터를 학습하는 알고리즘
데이터
어떠한 문제를 해결하기 위해 그에 알맞은 데이터 포맷을 요구
- Classification
- Semantic segmentation
- Detection
- Pose Estimation
- Visual Q&A
Loss function
오차를 판별하고, 가중치를 수정할 기준을 정의
Generalization; 일반화
학습 성능과 테스트 성능에 대한 차이 정도
Regularization
Generalization을 위한 규제를 정의
- Early stopping
- Validation error가 최저인 점을 기준으로 n회 동안 발전이 없을 시 학습 종료
- Parameter Norm Penalty; Weight decay
- 네트워크 가중치 수들이 크기 관점으로 작을수록 좋다는 가정을 수립
- Data Augmentation
- 데이터의 특징을 살려서 데이터를 늘리는 기법
- Noise Robustness
- 입력 데이터에 Noise 삽입
- Weight에 Noise 삽입
- Label Smoothing
- Mixup/CutMix와 같은 전처리 시 강아지 0.5, 고양이 0.5… 이런식으로 label을 다양화
- Batch Normalization
- 평균과 분산등을 통해 정규화 진행
Over/Under fitting
- Overfitting(과적합)
- 학습 데이터에 대해 우수한 성능을 보이나 학습을 진행하지 않은 테스트 데이터셋에 대해 낮은 성능을 도출하는 현상
- 학습 데이터를 깊이 학습하여 나타나는 현상
Generalization gap: 특정 에폭에 대해 학습 정확도(loss)와 테스트 정확도(loss)의 차이
Cross-Validation; K-fold validation
- 학습용 데이터를 k개로 쪼개어 각각의 partition을 해당 학습의 validation으로 이용
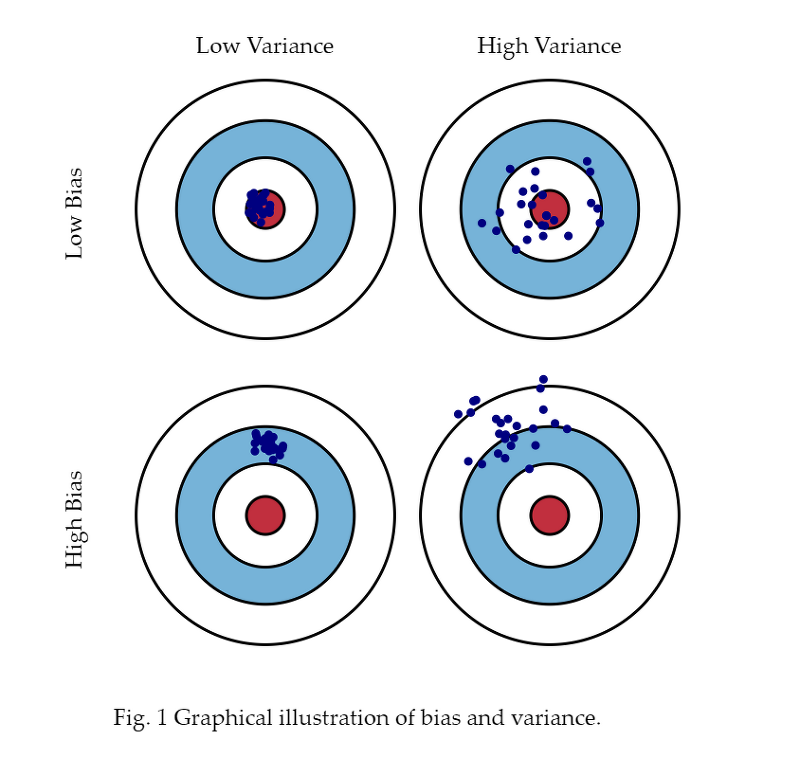
Bias vs Variance
- Bias
- target위치와 떨어져있는 정도
- Variance
- 집단이 퍼져있는 정도
bias and variance tradeoff: bias 혹은 variance를 조정하기 위해 데이터에 노이즈가 삽입되었다고 가정할 때, 서로 간의 Tradeoff 관계 형성
- 집단이 퍼져있는 정도
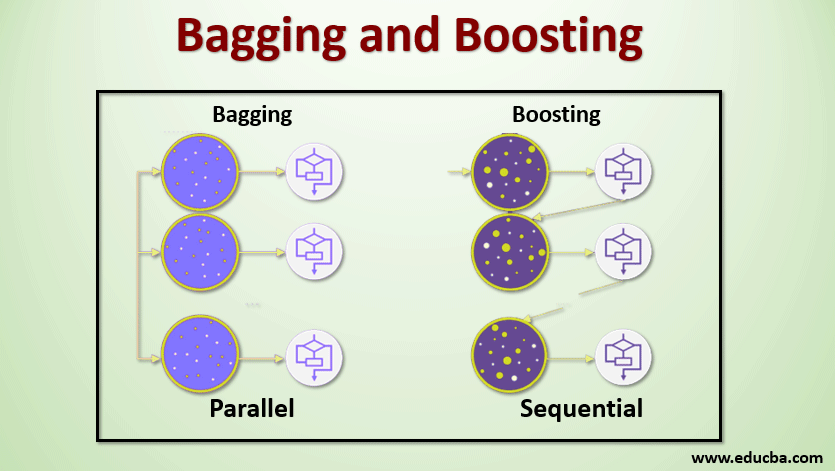
Bootstraping
학습 데이터가 고정되어있다고 가정할 때, Subsampling된 데이터를 기반으로 여러 모델을 통해 metric을 추출하여 결과를 분석
- Bagging(Bootstrapping aggregating)
- 일반적인 Bootstraping 기법을 의미
- 데이터를 100% 사용한 모델에 비해 Subsampled 데이터를 학습하여 도출된 metrics를 분석하는 것이 더 좋은 성능을 도출할 경우도 다수 존재
- Boosting
- Subsampled 데이터를 학습한 모델들의 결과를 Sequential하게 취급하여 가중치 학습과 유사하게 처리함으로써 하나의 모델로 도출
최적화
Gradient Descent
- $\eta$: 학습률
- $g_t$: 이전 gradient
Practical Gradient Descent
- Stochastic gradient descent
- 하나의 데이터에 대해 경사하강법 진행
- Mini-batch gradient descent
- Subset 데이터에 대해 경사하강법 진행
- Batch gradient descent
- 전체 데이터에 대해 경사하강법 진행
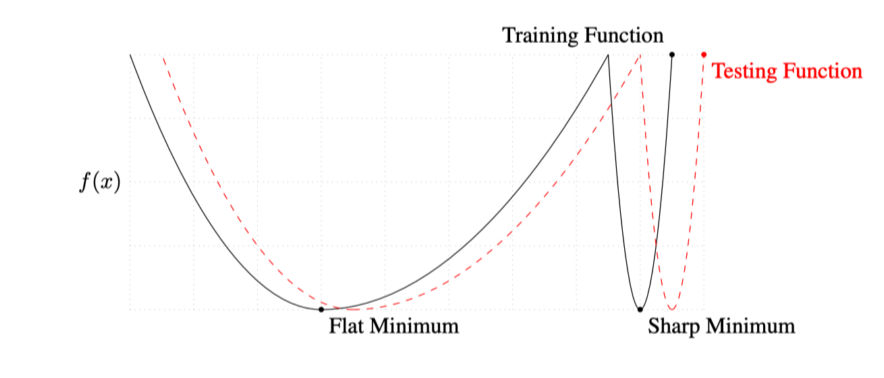
Batch-size Matters
Batch size의 값을 작게 적용하면 Flat minimizer에 도달하고, 크게 적용하면 Sharp minimizer에 도달
- Generalization 성능이 향상
- Train 성능과 Test 성능의 유사성을 실험적으로 도출
Stochastic Gradient descent
데이터의 일부(Batch)만을 이용하여 경사하강법 적용
- $W_{t+1} = W_t - \eta g_t$
Momentum
SGD 미분 값에 관성을 적용하여 갱신
- 빠른 수렴을 유도
- $\beta$: momentum
- $a_{t+1} = \beta a_t + g_t$
- $W_{t+1} = W_t - \eta a_{t+1}$
Nesterov Accelerated Gradient(NAG)
Momentum 적용 후의 위치에서 기울기를 고려
- $\nabla L(W_t - \eta \beta a_t)$: Lookahead gradient
- $a_{t+1} = \beta a_t + \nabla L(W_t - \eta \beta a_t)$
- $W_{t+1} = W_t - \eta a_{t+1}$
Adagrad
과거를 보았을 때, 적게 변화한 가중치에 대해서 큰 변화를 유도
- $G_t$: 지금까지의 gradient 제곱의 합
- $W_{t+1} = W_t - \frac{\eta}{\sqrt{G_t + \epsilon}}g_t$
Adadelta
Adagrad에서 $G_t$가 커지는 현상을 완화
- 학습률이 없는 학습법
- $G_t = \gamma G_{t-1} + (1 - \gamma)g_t^2$
- $W_{t+1} = W_t - \frac{\sqrt{H_{t-1} + \epsilon}}{\sqrt{G_t + \epsilon}}g_t$
- $H_t = \gamma H_{t-1} + (1 - \gamma)(\Delta W_t)^2$
RMSprop
Adagrad에서 $G_t$가 커지는 현상을 완화하기 위해 지수 이동 평균을 이용하여 영향력을 상쇄
- $G_t = \gamma G_{t-1} + (1 - \gamma)g_t^2$
- $W_{t+1} = W_t - \frac{\eta}{\sqrt{G_t + \epsilon}}g_t$
Adam
Momentum을 확보한 Adaptive 기법
- $m_t$: Momentum
- $v_t$: EMA of gradient squares
- $m_t = \beta_1 m_{t-1} + (1-\beta_1)g_t$
- $v_t = \beta_2 m_{t-1} + (1-\beta_2)g_t^2$
- $W_{t+1} = W_t - \frac{\eta}{\sqrt{v_t + \epsilon}}\frac{\sqrt{1-\beta_2^t}}{1-\beta_1^t}m_t$
Recurrent Neural Networks(RNN)
Autoregressive model
과거의 Time span을 고정하는 기법으로, AR(n)일 시, 과거 n 스텝에 의존
Markov model
직전 스텝의 과거에 의존하는 기법
- 이때 껏의 많은 정보를 포기
Latent autoregressive model
과거 정보를 요약하는 Hidden State를 형성
RNN; Vanila RNN
Short-term dependencies
- Hidden State를 보유하여 과거를 기억하는 노드 형성
- 멀리 있는 기억 노드에 대해서 점차 잊게 되는 한계보유
- Gradient Vanishing/Exploding 현상 발생
| RNN 구조 | Gradient Vanishing/Exploding |
|---|---|
 |  |
Long Short Term Memory(LSTM)
3개의 입력을 받아 과거의 정보 유실 정도를 결정
- 입력(출력)
- Input(Output): 현재 노드의 입력(출력)
- Previous(Next) cell state: 이전(현재)까지의 노드 정보를 취합하여 요약
- Previous(Next) hidden state: 이전(현재) 노드의 output
- 출력
- Output
- Next cell state
- Next hidden state
- Gate
- Forget gate: 정보의 유용함을 판단하여 현재까지의 정보(Cell state) 중 버릴 정보를 조정
- Input gate: 현재 정보에서 Cell state에 등록할 정보를 선택
- Output gate: 최종적으로 조작하여 다음 노드로 전달할 정보를 정리
<img src = /static/img/Study/AI/lstm_summary.png height = 400px>
GRU
LSTM 구조에서 Gate를 2개로 줄여 구조적 단순함 식별
Transformer
기존 seq2seq 모델과 달리, Attention 기법을 적용한 NLP 모델
- Encoder
- Feed Forward Neural Network와 Self-Attention으로 구성
- Self-Attention
- 여러 언어가 Encoder의 입력으로 들어갈 때 각 단어가 다른 단어를 고려하여 인코딩
- Feed Forward Neural Network
- Self-Attention을 통해 인코딩된 각 단어를 일대일로 변환
![]()
예시 문장: The animal didn`t cross the street, because it was too tired
위의 예시 문장에서 it이 무엇을 지칭하는지 아는 것이 번역의 핵심으로 취급한다.
Self-Attention기법을 통해 it이라는 단어가 그 외의 모든 단어들과 비교하여 연관성을 학습한다.
Convolution Neural Network(CNN)
Convolution
|Filter 연산| |:-:| |<img src=/static/img/Study/AI/convolution_0.png height=300px>|
| CNN 청사진 예시 |
|---|
| <img src=/static/img/Study/AI/convolution_1.png height=200px> |
Stride
- 슬라이딩 간격 설정
Padding
- 영상의 테두리에 일정한 값을 주입하여 사이즈 확대
연산
- 예시
- Padding = 1, Stride = 1
- Input: 40*50*128
- Kernel: 3*3
- Output: 40*50*64
- Parameter: 3*3*128*64
1*1 Convolution
Dimension reduction을 위한 기법
- Parameter 수를 줄이면서 깊이를 보존
- Bottle neck architecture