| 분류 | 팀 프로젝트 |
| 참여 인원 | 5명 |
| 소속 | Boostcamp AI Tech |
| 개발 기간 | 2022.12. ~ 2023.02. |
| 비고 |
📘 프로젝트 소개
개요
본 프로젝트는 기존의 모자이크를 대체하여 사람을 특정할 수 있을 정도로 얼굴을 노출시키지 않는 동시에 얼굴 표정, 시선, 눈빛과 같은 정보는 보존할 수 있는 새로운 방식을 제안합니다.
본 프로젝트의 궁극적인 목적은 인적 자원을 감소하여 초상권 침해 방지와 영상의 분위기를 유지하는 데에 있습니다.
개발 환경 & 아키텍처
- Infra:
BashAnaconda - Object detection:
YoloV7 - Tracking:
BoT-SORT - Cartoonize:
White-box Cartoonization - Backend:
FastAPI - Frontend:
Streamlit
📜 개발 방법
Model Pipeline
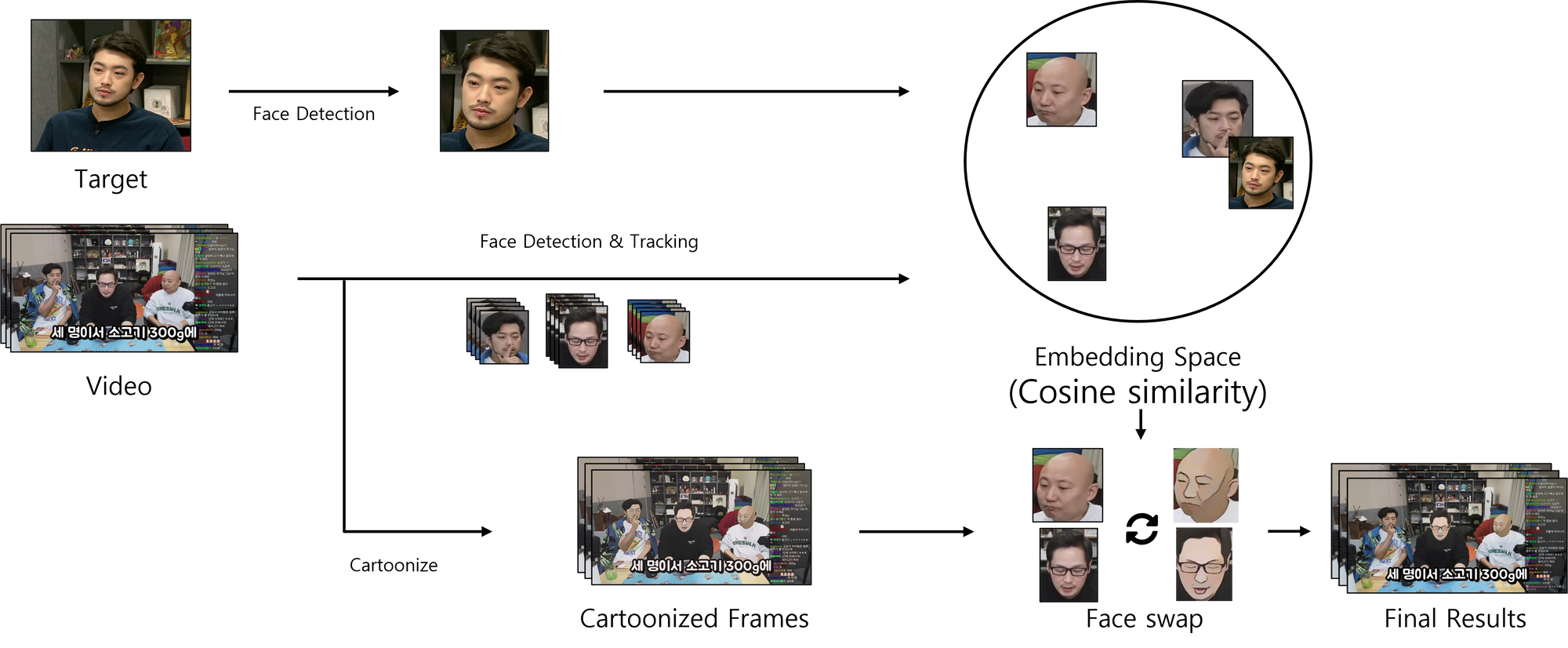 모델 파이프라인
모델 파이프라인
- 사용자로부터 영상과 영상의 주인공(target) 사진을 입력받는다.
- 사진, 영상에 face detection & tracking, cartoonize를 적용한다.
- 영상에 대한 face detection, tracking을 통하여 모든 등장인물의 얼굴 영역를 얻는다.
- 영상의 모든 프레임에 대한 cartoonize를 진행한다.
- 사진에 대한 face detection을 통해 주인공의 얼굴 영역를 얻는다.
- 주인공 사진과 영상에 등장하는 인물들의 사진에 대한 feature를 뽑아낸 후, cosine similarity를 계산하여 target과 target이 아닌 얼굴들을 구분한다.
- target이 아닌 얼굴들에 대한 정보(from 2-1)를 이용하여, 모든 프레임의 얼굴을 swap 한다.
Face Tracking
![]() Face Tracking 구조
Face Tracking 구조
BoT SORT(Bag of Tricks for Simple Online and Real-time Tracking)- 빠른 속도와 간단한 알고리즘으로 좋은 성능의 tracking을 구현
- Kalman filter를 현재 프레임의 detection 결과와 예측한 bbox를 IoU과 appearance정보를 사용하여 매칭
Robust Tracking with Face Re-identification
- 화면 전환이 빈번하게 발생하는 영상들에서 face tracking을 할 경우 화면이 넘어갈 때 서로 다른 인물의 얼굴이 우연히 화면의 같은 위치에 존재한다면 다른 사람임에도 동일한 Tracklet으로 판단
- 각 인물의 tracking 결과 마다 하나의 대표 bounding box를 뽑는 과정에서 다른 인물이 tracking 결과를 대표하게 되는 문제점이 발생
- 단순히 bounding box간 IoU에만 근거하여 tracking을 하는 것이 아니라, IoU가 높더라도 bounding box의 feature간 일정 수준이상 유사하지 않으면 tracking을 공유하지 않도록 face
re-identification을 사용
Cartoonize
 Cartoonize 항목 및 특징
Cartoonize 항목 및 특징
- Cartoonize: Neural Style Transfer GAN 기법을 이용한 만화화 기법을 명명
- 얼굴만 cartoonize하는 모델의 경우(Toonify, Facial Cartoonization, StyleGAN), 영상에 등장하는 얼굴 수에 비례하여 inference 횟수 증가
- 전체 이미지를 Cartoonize하는 모델의 경우, 한 번의 inference를 진행하여 얼굴 영역만 crop하여 사용하면 되므로 일정한 서비스 시간을 제공
- 서비스 시간과 Cartoonize된 결과물의 완성도를 고려하여
White-Box cartoonization을 채택하였다.
얼굴 유사도 검사
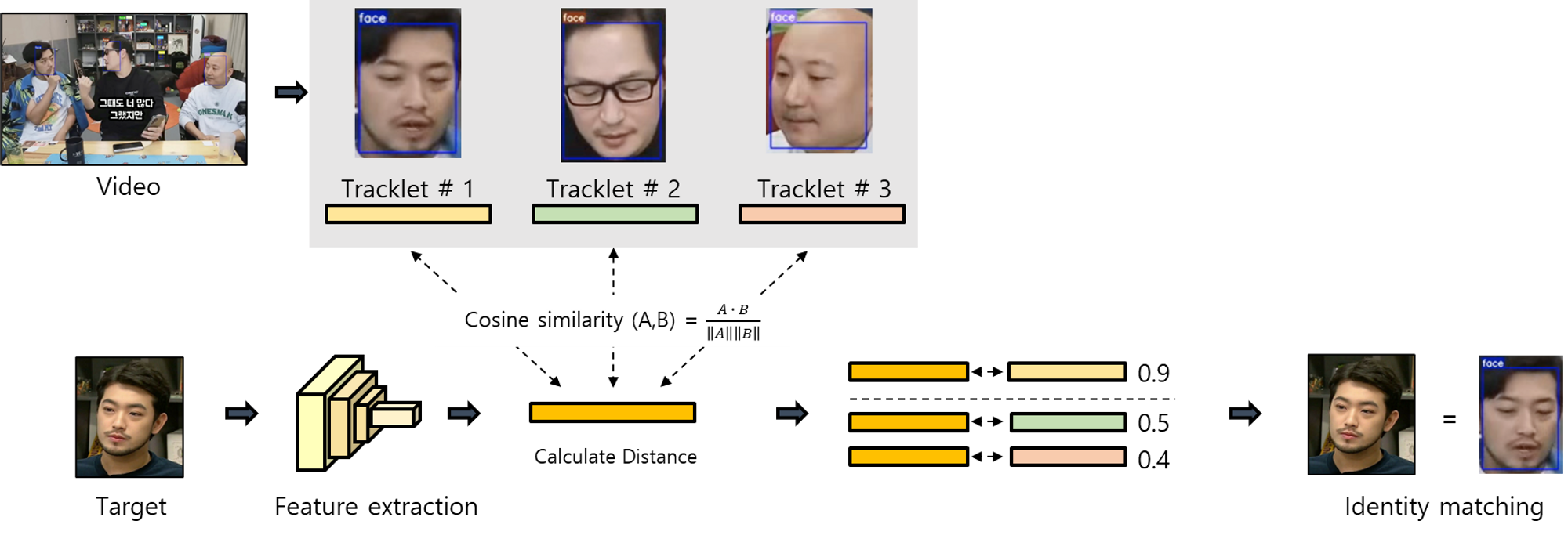 유사도 검사 요약도
유사도 검사 요약도
- 영상에서 tracking을 수행한 각각의 결과(tracklet) 대해 confidence score를 기반으로 tracklet을 대표하는 bbox를 한 개씩 선택한다.
- target image와의 similarity를 계산한다.
- target image와 계산된 similarity를 통해 같은 인물에 대한 매칭 결과를 얻을 수 있도록 유사도 검사를 두 단계로 수행한다.
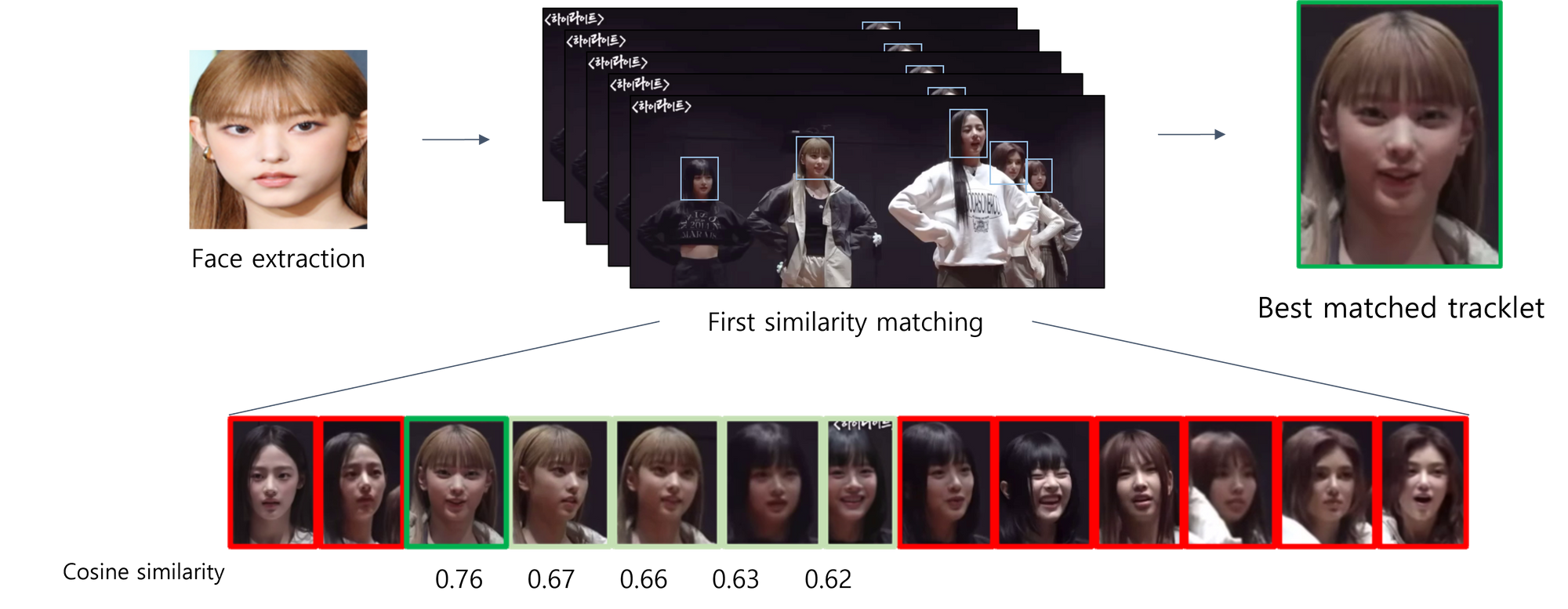 1차 유사도 검사
1차 유사도 검사
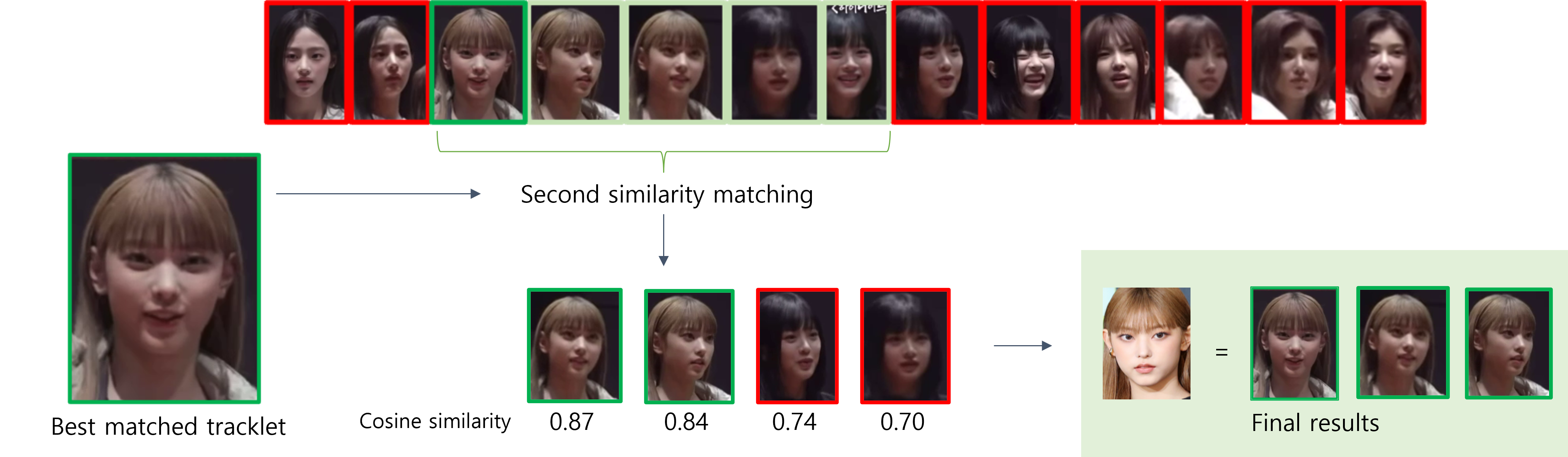 2차 유사도 검사
2차 유사도 검사
- 1차 유사도 검사를 통해, target image에 대해 tracking된 image 중 가장 유사도가 높은 얼굴을 추출
- 2차 유사도 검사를 통해, 1차에서 추출한 target image와 가장 유사하다고 판단한 얼굴과 tracking된 image들로 유사도 검사를 수행
- 영상 내의 인물의 모습에 기반하여 매칭을 수행하므로, 유사도 검사 시 사용자가 제공한 다양한 target image에 대해 일관된 매칭 결과를 도출 가능
Face Swapping
- Tracking 및 Similarity Check 과정을 통해 얻은 주인공이 아닌 얼굴들에 대한 Bbox 정보를 이용하여, 모든 Bbox의 크기를 기존의 2배로 확장
- 해당 영역(얼굴)의 이미지를 cartoonize된 이미지로 대체하였으며, 단순히 해당 영역의 이미지를 덮어씌우는 경우 이미지의 경계가 부각되는 부자연스러운 장면을 생성하므로 pixel-wise weighted sum을 통한 edge smoothing을 고안
- 이미지에 곱해줄 weights를 만드는 방식으로 총 세 가지 방법을 구성
- 각 pixel과 영역 중심 pixel 사이의 L1 distance 계산 후 normalize, thresholding 하여 사용
- 각 pixel과 영역 중심 pixel 사이의 L2 distance 계산 후 normalize, thresholding 하여 사용
- 이미지의 중심 영역은 1로 설정하고, 이미지의 경계에 가까워 질수록 0에 가까운 값을 padding 하여 사용(선별)
- 이미지에 곱해줄 weights를 만드는 방식으로 총 세 가지 방법을 구성
 최종 edge smoothing
최종 edge smoothing
Service Flow
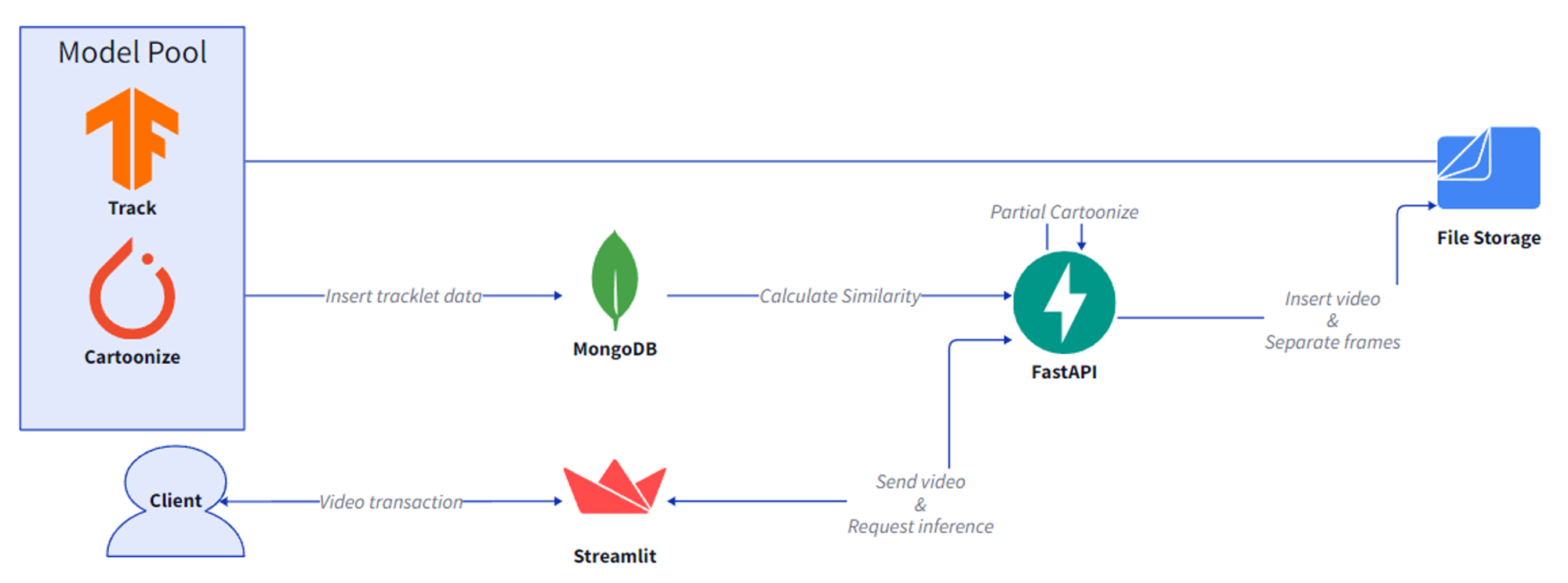 서비스 흐름 요약도
서비스 흐름 요약도
Streamlit을 통해 사용자와 상호작용하며, 주인공 이미지와 영상을 입력받고, 결과물을 다운로드할 수 있다.Streamlit을 통해 입력받은 이미지와 영상은 Server file storage에 저장되며,FastAPI를 통해 Detection & Tracking, Cartoonize 연산을 요청한다.- Detection & Tracking은
PyTorch환경에서 실행되고, Cartoonize는 Tensorflow 환경에서 실행된다. 이 과정은 병렬적으로 진행되며, Tracking 결과는MongoDB에 저장한다. - 위의 과정이 끝난 이후, backend에서
MongoDB에 저장된 tracking 정보를 사용하여 Face swapping 과정을 수행한다. Streamlit을 통해 사용자가 최종 결과물의 재생 및 저장한다.
Result
| Target | Before | After |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
Discussion
- 첫 번째 결과의 tracking result를 보면 배경 및 의상에서도 얼굴이 인식되는 것을 확인할 수 있다. CAFE는 confidence thresholding을 통해 이러한 상황에서도 강인하게 동작한다.
- 두 번째, 세 번째 결과를 보면 화면 전환에 의해 동일 인물에 대한 여러 개의 tracklet이 생성되지만, 우리가 제안한 two-step similarity check 과정을 통해 성공적으로 target과 extra를 구분하여 주인공이 아닌 인물들에 대해 일관된 cartoonize를 적용하는 것을 확인할 수 있다.
영상 출처
- https://www.youtube.com/watch?v=SP-LJqVgQuw
- https://www.youtube.com/watch?v=GmAwsAB7nhw
- https://www.youtube.com/watch?v=tL20swtWOqI
👪 역할 및 개발 내용
- 협업 증진
- Git 활용 예제 코드 작성
- 개발 인프라 구축
- 협업을 위한 공동 템플릿(개발 환경) 제작
- Bash shell script 기반 개발 환경 구축
- 개발 프로세스 구축
- Micro-Service 지향 Architecture 구성
- 모델 파이프라인을 직접 설계하고 구축
- 기능 연계를 위한 코드 병합 주도
- Product Serving
- Frontend의 View 기능들을 비동기적으로 수행함으로써 시각화 효과 상승
- 모델 추론 기능을 비동기적으로 수행함으로써 Inference 수행 시간 단축
💡 개발 경험 및 후기
한계점 및 아쉬운 점
- Docker in docker
- 모델의 파이프라인을 개략적으로 설계한 결과, 실질적으로 기능마다 요구하는 사양이 크게 차이가 나
Docker-Compose환경을 고안 - 제공하는 서버는 이미 Container 환경으로 Docker in docker에 대한 권한 부재
- 피치 못해 Anaconda 환경으로 여러 개의 환경을 구상하여 같은 터미널 상에서 Background로 서버를 개설하도록 수정
- 모델의 파이프라인을 개략적으로 설계한 결과, 실질적으로 기능마다 요구하는 사양이 크게 차이가 나
- Container 환경의 제약
- Redis를 통해 데이터를 관리하고
Kafka,RabbitMQ를 통해 서비스 환경 변수 등 비동기 데이터를 공유하도록 설계 및 경험 유도 - 해당 오픈소스를 설치하고 나면 재부팅이나 서비스 재시작을 유도하지만 Container 내부에서
reboot,systemctl명령어에 대해 제한 - 본 제약에 따라,
MongoDB를 사용하여 서비스 시작 시 Backend에서 환경 변수 데이터를 넣고 다른 환경에서는 이를 호출하여 활용
- Redis를 통해 데이터를 관리하고
후기
- 설계와 협업을 잘 하자
코드를 병합할 때, 팀원들이 작성한 코드를 다시 함수화하여 Controller로 호출하도록 구조화하여야 했다. 하지만 명세가 구체적으로 설계되지 않아 팀원들이 작성한 코드를 일일이 이해하고, 재수정하는 작업을 거쳐야했다. 본인이 필요한 형태에 대한 명세를 구체적으로 제시하지 않아 일어난 일로 생각하여, 책임감에 밤새 코드를 수정하였고, 코드를 일관화 하였다. 이후, 팀원들이 ‘코드 수정은 이를 개발한 팀원과 같이 했으면 빠르게 할 수 있었을 것이다’라고 해 주었고, 이러한 말들에 책임감으로써 부담을 짊어지고 본 과정를 수행했다는 점에서 팀의 기능을 제대로 작동시키지 못한 것 같아 많이 반성하게 되었다.
- Product serving 퀄리티
개발에 장벽이 너무 많다. 주어진 환경은 Container 환경이기 때문에 외부 오픈소스 활용 등 개발 환경에 큰 제약이 따랐다. 뿐만 아니라 AWS나 GCP와 같은 클라우드 서비스도 활용하고자 하였지만, Product serving의 전반적인 부분을 담당하다 보니 기존에 학습하지 않은 클라우드 서비스까지 적용하기엔 너무 큰 부담으로 느껴졌다. 또한, 환경마다 사양이 다른 서비스인 만큼 쿠버네티스도 적용하고 싶다는 생각이 들었다. 컴퓨터 공학을 재학하면서 많은 것을 경험해보았다고 생각했지만, 아직 부족했다는 것에 많은 회의감을 느꼈다. 추후 개선하게 된다면 위의 문제점들을 해결하여 더욱 완성도 높은 서비스를 제작하고자 한다.
- 우수한 팀
언제나 웃음이 끊인 적이 없는 최고의 팀이다. 내가 지방에 살다보니 서울 오프라인 미팅 때 교통비를 거리낌없이 지원해주거나, 밤을 새거나 협업하는 데 함께 있어주거나 도와주는 등 항상 빚지기만 했던 것 같다. 마지막 프로젝트인게 많이 아쉬울 정도로 좋은 팀이었다. 다양한 인간관계에서 협업을 진행하면서 트러블이나 갈등이 있기 마련인데 이러한 점들을 진짜 갈등으로써 잘 풀어 나갔다. 막 임팩트 있는 팀은 아니었다고 생각했지만, 오프라인 미팅에서 운영진 님들과 적극적으로 소통하고, 멘토님과도 적극적으로 활동을 이어나가는 등 시간이 갈수록 우수한 팀으로 거듭하는 느낌이 들었다. 아직은 지방에 있어서 많이 아쉽지만, 꼭 많은 곳에서 함께 했으면 좋겠다.